


Des détails qui font toute la différence
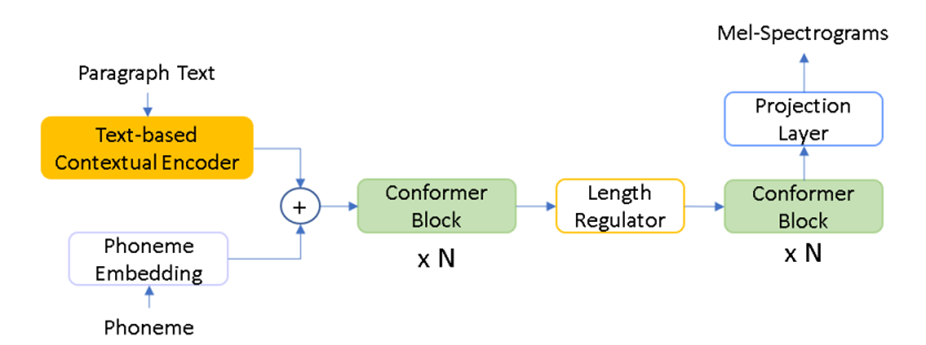
In this blog, we introduce a new technical innovation that considers contextual information to model TTS voices for paragraph or long-form content reading. This new technology significantly improves the coherence and expressiveness when generating long audios, using Paragraph MOS (Mean Opinion Score) as metrics. With this new technology, we are glad to announce the public preview of Roger, a contextual voice model in English (US), to enable customers to generate more expressive and natural-sounding long-form audio content using Azure Neural TTS service.
via LinkedIn : lire l’article source

Laisser un commentaire