


DeepMind describes and documents the current capabilities of Gato, their new multi-modal, multi-task, multi-embodiment generalist policy.
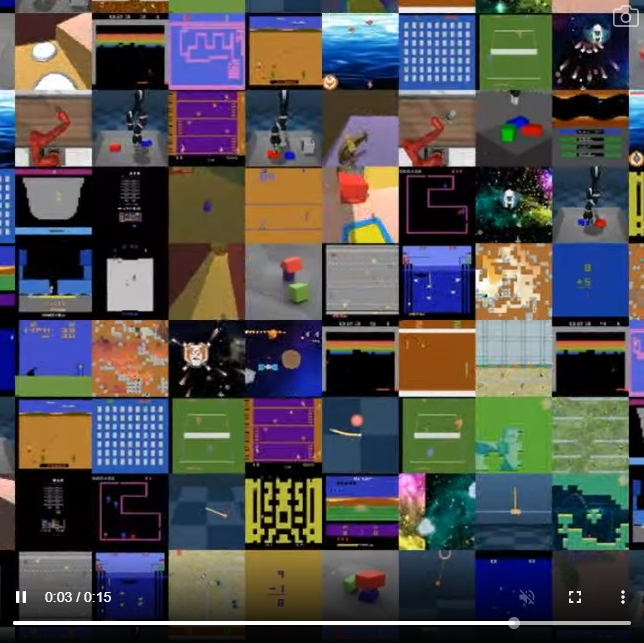
Inspired by progress in large-scale language modelling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
via Deep Learning Weekly : lire l’article source

Laisser un commentaire