


Intéressant de voir la difficulté de la lecture sur les lèvres
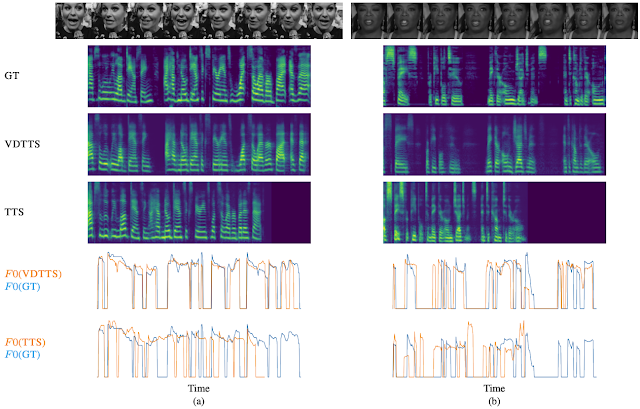
In “More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech”, we present a proof-of-concept visually-driven text-to-speech model, called VDTTS, that automates the dialog replacement process. Given a text and the original video frames of the speaker, VDTTS is trained to generate the corresponding speech.
via Chrome : lire l’article source

Laisser un commentaire