


L'intelligence artificielle permet de générer des voix de synthèse de plus en plus réaliste. C'est ce qu'on appel des NeuroVoices. Depuis quelques mois Microsoft permet de fabriquer des NeurosVoice spécifique. C'est ce que j'ai fais avec ma voix.
Vous l'aurez compris c'est le même principe que les DeepFakes que j'avais expérimenté avec un Zoom Bombing de Emmanuel Macron sauf que cette fois c'est de l'audio avec un resultat vraiment professionnel.
La démo !
On commence par une petite démo, dans laquelle je vais m'enregistrer sur Audacity en lisant un texte. Puis le même texte généré par ma NeuroVoice.
Ceci est un enregistrement vocale permettant de tester les voix neurale personalisées de Microsoft. Je suis l'enregistrement humain/synthétique.
Le champ des applications est énorme ! Que ce soit pour l'enregistrement d'un Podcast, automatiser le montage des voix-off d'un reportage, des conseils beauté d'une égérie de marque, les acteurs d'un animé ou des fictions audio ?!
Préparation du Projet
Attention ! "great powers comes with great responsibility" la fabrication d'une NeuroVoice implique beaucoup de préparation.
- Vous devez être une entreprise
- Avec l'accord ecrit et vocal d'un "Voice Actor"
- Expliquer un cas d'usage bien spécifique
- Dans lequel l'utilisateur sera prévenu (ne pourra pas être trompé)
- Il faut enregistrer minimum 300 échantillons audio en qualité studio avec le transcript associé.
- L'entrainement prends 20-30 Compute Hour (52$/h) sur un tenant US/UK/Asie
- Prévoir des couts liés à l'usage du modèle ($24/million de caractère et $4.04 / heure d'uptime .
Ensuite il est possible de rapatrier le modèle entrainé sur votre tenant FR.
Enregistrement Audio
La documentation est très bien faite et Deb Adeogba à rédigié un excellent article étape par étape avec des scripts en français. Voici quelques conseils complémentaires.
Matériel
J'utilise un Microphone Yeti combiné avec l'utilitaire Krisp pour supprimer les bruits statiques de l'USB et parasites du ventilateur du portable.
Enregistrement
L'enregistrement est fait avec Audacity Ca m'a pris environ 12h pour capturer 450 échantillons de voix. Puis quelques heures pour asjuter les alertes remontée par le Speech Studio.
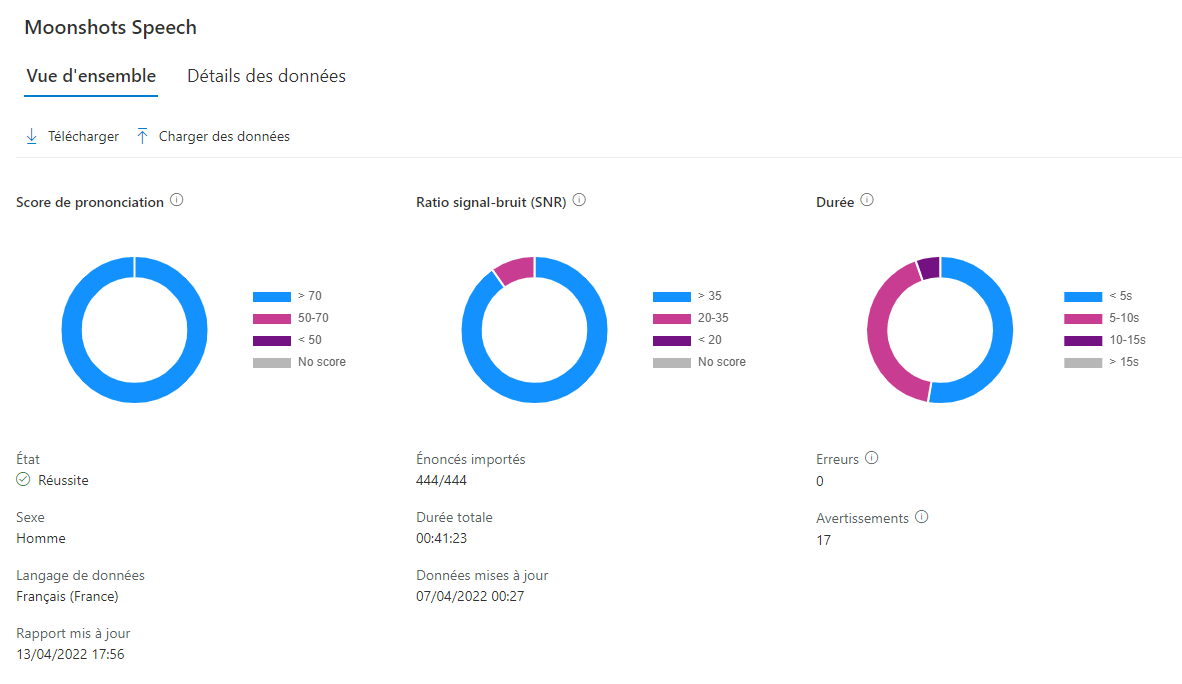
J'ai surtout eu des erreurs d'inatention (mots manquant, silence). quelques bugs étranges sur la prononciation, un volume trop élevé sur les exclamations.
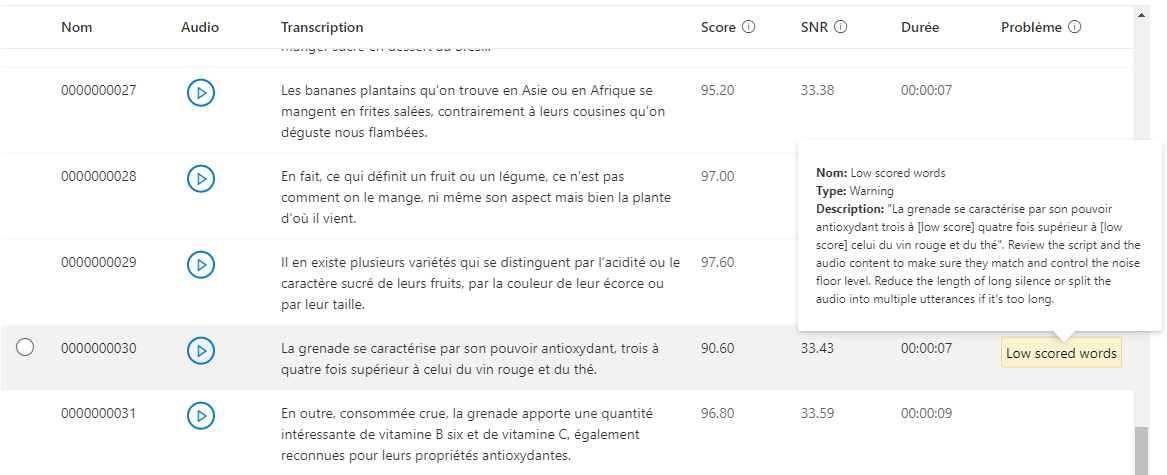
L'ergonomie du studio est très fonctionnelle malgré quelques petits bugs de libellé. Il manque quelques tri et traitement par lots ou réédition à la volée mais ça fonctionne très bien déjà.
Entrainement et Déploiement
Et voilà ! Il ne reste plus qu'a entrainer le modèle pendant une 20aine d'heure et le déployer. Il est possible de suspendre/activer le end-point via l'interface ou API pour limiter le cout des $4.04 / heure.

Le déploiement est assez lent (plusieurs minutes). Maintenant direction la documentation pour quelques requêtes REST et une intégration dans Node-RED et Reflets.io …
Reflets.io
Voici une petite démo très simple intégrée au miroir qui vient compléter les autres démos de reconnaissance vocale, visuelle, faciale, multilangue…
Pour la forme j'interroge GPT-3 sur une recette de pâque, traduite ensuite en français et lu. Il y a encore quelques petits détails qui accrochent mais le resultat est quand même bluffant.

Laisser un commentaire