Catégorie : 🧠 Artificial Intelligence
-
Nouvelle fonctionnalité de mouvement pour ajouter du dynamisme à vos images

La nouvelle fonctionnalité '/move' permet d'ajouter du mouvement à vos images préférées. Une vidéo de démonstration montre comment combiner du matériel vidéo de danse avec la beauté IA générée par @TensorArt en utilisant '/move'. Quelques astuces sont également partagées, comme utiliser des images identiques pour la vidéo et la composition, éviter les vidéos avec trop de mouvement, et faire correspondre…
-
La chanson générée par une IA d’un texte viral de la Licence MIT devient virale

L'IA Suno.ai permet à n'importe quelle série de mots de devenir des paroles de chanson, y compris des blagues internes. Un ingénieur a tweeté une chanson générée par l'IA avec les paroles de la Licence MIT et elle a rapidement circulé dans la communauté de l'IA en ligne. Suno est une entreprise qui a été formée en 2023 et qui…
-
Machine learning driven teleprompter
Microsoft is bringing AI to broadcast news. The company wants to patent systems for a “machine learning driven teleprompter.” via PatentDrop : lire l’article source
-
Join the waitlist for KaraVideo.AI, the revolutionary video generator powered by OpenAI Sora

Don't miss out on the opportunity to be one of the first to experience Sora! Join the waitlist for KaraVideo.AI, an incredible video generator powered by OpenAI Sora. With its advanced capabilities, KaraVideo.AI is set to revolutionize the way videos are created. Don't wait, sign up now and be at the forefront of this exciting technology! via Meta Media :…
-
Microsoft annonce la disponibilité de 9 nouvelles voix réalistes pour une interaction plus naturelle avec les bots

Il manque encore de l'émotion dans la voix. La clef est a mon sens la variation dans le ton.
-
OpenAI propose un modèle d’IA de clonage vocal qui ne nécessite qu’un échantillon de 15 secondes pour fonctionner
OpenAI offre un accès limité à une plateforme de génération de texte en voix qu'elle a développée appelée Voice Engine, qui peut créer une voix synthétique basée sur un extrait de 15 secondes de la voix de quelqu'un. La voix générée par l'IA peut lire des instructions textuelles sur commande dans la même langue que celle du locuteur ou dans…
-
Pixart-α: A Faster and High-Quality Text-to-Image Diffusion Model
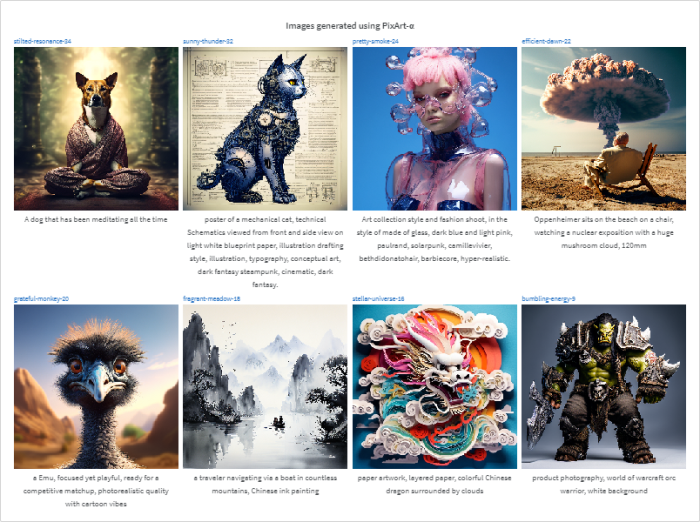
Pixart-α is a new text-to-image diffusion model that can generate high-resolution images with competitive quality while requiring significantly less training time compared to other models. This article explores the architecture and training strategy of Pixart-α, as well as how to run it using HuggingFace Diffusers and manage experiments with Weights & Biases. The article also compares the image quality of…
-
Intel et Microsoft discutent des plans pour exécuter Copilot localement sur les PC au lieu de le faire dans le cloud

La réponse au move d'NVIDIA et surtout un soucis de faire bosser Intel aux US
-
StableVITON: Améliorer l’essai virtuel de vêtements avec l’attention croisée

StableVITON est une méthode améliorée d'essai virtuel de vêtements qui utilise une carte agnostique, un masque agnostique et une pose dense en entrée pour le modèle U-Net pré-entraîné. Il utilise également un mécanisme d'attention croisée pour aligner et préserver les détails des vêtements. Les résultats montrent que StableVITON produit des images de haute qualité même avec des arrière-plans complexes. via…