


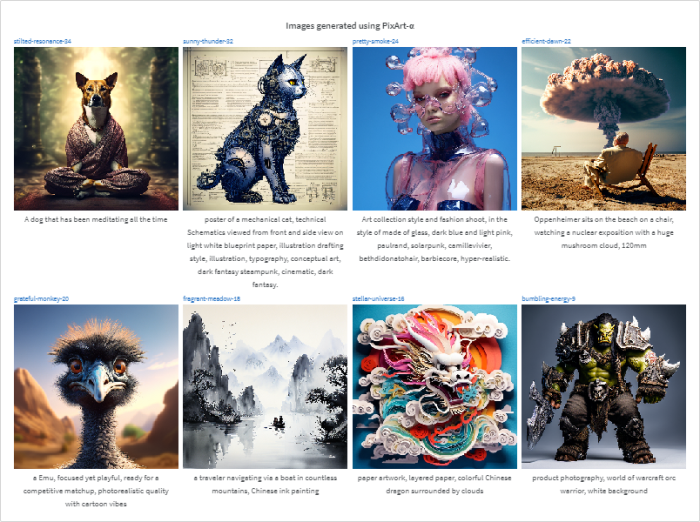
Pixart-α is a new text-to-image diffusion model that can generate high-resolution images with competitive quality while requiring significantly less training time compared to other models. This article explores the architecture and training strategy of Pixart-α, as well as how to run it using HuggingFace Diffusers and manage experiments with Weights & Biases. The article also compares the image quality of Pixart-α with Stable Diffusion XL, a state-of-the-art text-conditional image generation model.
via Deep Learning Weekly : lire l’article source

Laisser un commentaire