Enjeux de performance et scalabilité
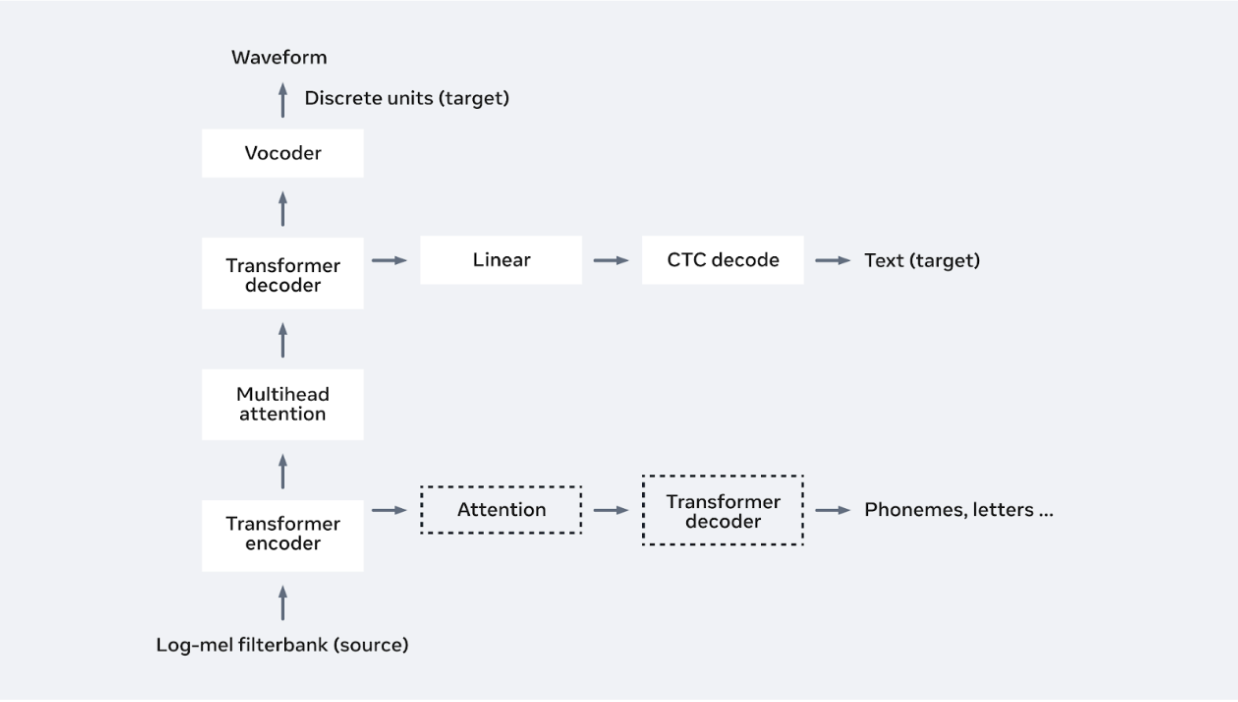
Advancing direct speech-to-speech modeling with discrete units
via Chrome : lire l’article source



Enjeux de performance et scalabilité
Advancing direct speech-to-speech modeling with discrete units
via Chrome : lire l’article source

Laisser un commentaire